
DÉVELOPPEMENT
Legacy to DDD : Partie 3 - Tester et faire du neuf avec Domain-Driven Design en PHP
Publié le : 4 Avril 2023
59 min.
Partager
Cet article fait suite à nos deux précédents articles sur le DDD et son application à un projet vieillissant, réalise en CakePHP. Dans la première phase, nous avons passé deux actions essentielles en mode DDD : une lecture et une écriture.
Puis nous avons creusé les avantages que nous offre le DDD. À présent revenons sur la qualité de notre code et offrons-nous des perspectives d’infrastructure plus moderne.
Pour retrouver les premières parties :
- Legacy to DDD : Partie 1 - Comment transformer son code existant en utilisant des concepts concrets de Domain Driven Development
- Legacy to DDD : Partie 2 - Comment moderniser votre application PHP avec le Domain-Driven Design
6. Tester
6.1. un cœur éprouvé par phpunit
Revenons dans la continuité du point 4.3. Passons à l’écriture de quelques test phpunit. Mais avant cela, il va nous falloir faire de la place car Cakephp vient avec sa propre configuration de PHPunit.
Après cela il faut changer quelques chemins dans
et , puis l’ensemble des noms de domaine des tests cakephp.Les tests cakephp peuvent ainsi toujours être lancés avec cette commande.
À noter qu’ils ne passent pas dans l’actuel car il ne trouve pas les fixtures. Mais nous pouvons maintenant écrire nos propres tests. Savoir identifier quelles parties doivent être testées unitairement en priorité est simplifié par la découpe du code. Notamment, les validateurs que nous avons définis méritent toute notre attention pour pouvoir leur faire confiance. Écrivons donc un test en exemple pour le validateur de l’input de modification d’un bookmark.
On met ici en évidence que notre code est découpé de manière très atomique : chaque partie ne fait qu’une petite chose. Et ça devient alors très facile de la tester et de gagner en confiance sur le comportement de l’application. Le gain n’est pas évident dans ce cas, mais sur un projet complexe, on aura d’autant plus éclaté la complexité en petites briques parfaitement appréhendables.
Pour lancer ce test, il va nous falloir configurer phpunit dans le fichier
Puis lancer les tests.
Pour compléter cette partie sur les tests, voici le tests du validateur d’update d’un bookmark
Comme notre validateur a besoin du système pour retrouver l’utilisateur courant, on vient le simuler par un *mock*. Ensuite on lui fait faire ce qu’on veut selon les cas que l’on suite produire. Puis lancer les tests.
Voilà une bonne petite stack de tests, prête à recevoir tout les tests unitaires que vous voudriez écrire ! Pour clore cette partie, nous pouvons aussi appliquer php-cs-fixer aux tests depuis le fichier de configuration
Je compile tout ça dans ce commit pour vous : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/9c04e75c5646ead8ed2eab5482eaa5696e591cdc
6.2. Tests de bout en bout
Les tests unitaires sont pertinents pour s’assurer que les différents éléments rempliront bien leur rôle. Cependant, on ne peut pas se passer des tests d’un utilisateur humain qui va réellement se connecter à l’application et réaliser les différentes actions pour s’assurer que tout est opérationnel.
Alors, on va s’équiper d’un outil qui peut faire ce boulot de manière automatisée ! Il y a quelques années, j’aurais proposé Behat pour cette tâche, mais aujourd’hui, voici Ouvre une nouvelle fenêtreCypress ! Ajoutons-le à notre projet. Pour cela vous aurez besoin d’avoir pré-installé nodejs 14+ et npm.
On peut lancer immédiatement l’interface de cypress
Écrivons notre premier test sans attendre.
Ce test réalise les actions suivantes :
- Chargement de la page de login
- On entre email, mot de passe, puis on valide la connexion
- On vérifie qu’on est bien sur la page de la liste des bookmarks, puis on clic sur l’élément Let’s encrypt
- On vérifie qu’on est bien sur la page pour afficher un bookmark et son contenu
Cypress nous offre même un affichage en temps réel des actions qu’il réalise, et il s'arrête quand une condition n’est pas remplie.
Voilà un bien faible effort pour apporter une grosse valeur au projet : on sait que les fonctions essentielles sont remplies !
On voit cependant que ces tests sont dépendants de l’état courant de l’application, ce qui peut mener à des erreurs. Par exemple, si on renomme le bookmark LetsEncrypt en Free SSL Service, on voit bien que le test ne fonctionnera plus puisqu’il ne trouvera pas la chaîne de caractères. Pour résoudre ce problème, nous allons mettre en place un reset des données que nous réalisons avant chaque test, pour être sûr de nos données.
Puis il nous implémenter ce contrôleur côté Cakephp
Nous l’avons fait ici d’une manière rapide et non sécurisée. Pour une véritable application, il aurait été bien mieux de l’autoriser uniquement en environnement de test et de dev, et d’utiliser le système de fixtures de Cakephp. On va s’en tenir au minimum fonctionnel. Ensuite, on voit qu’on peut immédiatement mettre en commun certaines parties du code du test, à commencer par le nom de domaine pour atteindre l’application. Un peu de configuration ici :
Autre point : on commence le test par se connecter à l’application. On se doute bien que ce sera une action réalisée de manière récurrente, on va donc la placer à part.
Puis on s’en sert dans notre test
Ajoutons un nouveau test pour modifier un bookmark
Nous voici avec un joli petit outil, qui va nous assurer que les fonctions essentielles de l’application sont toujours remplies !
À noter que Cypress peut être lancé sans présentation visuelle, très utile pour lancer les tests dans le cadre d’une plateforme d’intégration continue. Il génère même des vidéos du déroulé des actions, précieux pour identifier les raisons d’une erreur.
Le résumé dans ce commit : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/f7a71e3f6a4d81e2c76c610c870c01fb139f7ae6
6.3. Une pseudo CI
Pour résumer, on s’est fait une belle petite stack de vérification de la qualité du code produit ! Si on osait, on exécuterai ces vérifications au moment de créer un commit. On va éditer le fichier
Cette technique n’est pas toujours pertinente, car on a parfois juste envie de créer un commit rapidement. Mais il est aussi très pratique de connaître au plus tôt les erreurs provoquées par nos derniers changements sans avoir à attendre une CI souvent surchargée. Quoi qu’il en soit, je vous conseille de limiter les vérifications faites ici aux plus rapides, c'est-à-dire d’en exclure les tests de bout en bout de cypress.
7. Faire du neuf
7.1. Nouvelle infra en cohabitation
À présent que nous avons une situation bien saine et solide, le métier vient vers nous et nous annonce que Google est intéressé par notre projet et souhaite communiquer avec notre application, via son API. Bien entendu, nous n’avons rien mis en place de ce côté.
C’est l’occasion rêvée pour relever le défi et mettre en place l’outil d’api parfait : Ouvre une nouvelle fenêtreApi-Platform.
Avant de commencer, nous allons isoler la configuration de Cakephp pour ne pas entrer en conflit avec celle de Symfony.
Il nous faut alors configurer cakephp dans ce sens
Continuons en installant les briques essentielles de Symfony, puis api-plaform.
Il nous faut maintenant diriger les requêtes HTTP vers Cakephp ou Symfony selon le path demandé.
il nous faut rassembler les deux dossiers racines pour le serveur http.
On relance pour prendre en compte ces changement
Puis, comme nous l’avons fait pour Cakephp, nous allons limiter symfony à une partie du dossier src
Ajoutons cette nouvelle partie des noms de domaine à composer.json
Ne pas oublier de mettre à jour l’autoload
On rencontre un autre souci également. Avec nos noms de domaines non standard dans le dossier src, on commence à avoir quelques soucis désagréables. Nous allons donc les uniformiser en les commençant tous pas ```App/```.
Puis mettre à jour le composer.json en fonction de cela.
Je vous épargne toutes les modifications mais vous les trouverez dans le commit que voici : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/270537eff57ce397208158681e38d93b4864b28d
Il nous faut également demander à Symfony de publier les assets de ses bundles pour les rendre accessibles dans le dossier public.
Au final, ça fonctionne ! Quand on se rend sur Ouvre une nouvelle fenêtrehttp://0.0.0.0:9050/users/login, on peut se connecter et réaliser toutes les opérations dans l’application Cakephp. Et quand on se rend sur Ouvre une nouvelle fenêtrehttp://0.0.0.0:9050/api/docs, on voit la page de swagger de description de l’Api, qui est vide pour le moment.
7.2. Nouvelle Doctrine
Nous allons utiliser Doctrine, l’ORM qui poussé par Symfony. Mais Doctrine a un paradigme opposé à l’ORM de Cakephp. La référence du modèle de données est basé sur les fichiers de définition des entités pour Doctrine, alors que Cakephp se base sur la structure de la base de données déjà existante.
Pour être en mesure d’utiliser là même base de données pour les deux infrastructures, il nous faut donc reproduire le modèle de données sous la forme de la configuration Doctrine. Nous allons le faire au format XML. Voici les 3 objets métiers : user, tag et bookmark.
Ces fichiers servent à indiquer à Doctrine comment les différentes propriétés des objets doivent être stockées en base de données, permettant de le transformer automatiquement vers la bdd, et quand on récupère les données de la bdd. C’est d’ailleurs le sens de l’acronyme ORM : Object Relation Mapper.
Comme vous pouvez le voir, les objets que nous souhaitons faire connaître à Doctrine sont directement les objets métiers tel que nous les avons défini dans la couche modèle. Cela nous évitera de mettre en place un mécanisme de conversion entre entité Doctrine et objet métier, comme nous l’avons fait pour la partie Cakephp. Cependant, nous ne devrions pas mettre les définitions des champs de la table dans les fichiers domaine (annotation), car on va mélanger les couches domaine et infrastructure en faisant cela. Voilà pourquoi nous avons choisi le format XML pour ces définitions.
Pour être complet, il nous faut modifier le fichier SQL de base (côté Cakephp) pour correspondre au nommages de Doctrine et pour fixer des types mieux adaptés.
La difficulté à manipuler deux infrastructures comme nous le faisons là, c’est qu’elles doivent rester en cohérence dans leur connaissance du monde extérieur, et notamment de la base de données. Il faut décider laquelle des deux sera maître pour gérer le modèle en bdd, et laquelle suivra cette structure. Pour notre cas, nous garderons Cakephp comme responsable dans cette tâche.
Si vous avez bien suivi, nous avons mis en place une incompatibilité dans la configuration du mapping de l’objet bookmark. En effet, la propriété url de cet objet n’est pas une chaîne, mais un value-object. Il va nous falloir expliquer à Doctrine comment stocker et récupérer cette donnée. Pour cela, on va créer un nouveau type Doctrine.
Cette classe est finalement assez claire. On définit un nouveau type qui étend le type string, car on va bien le stocker sous la forme d’une chaîne de caractères. On a là deux méthodes essentielles : comment on la convertit pour php, et comment on la convertit pour la bdd. Simple. Le reste est détail technique. Précisons à Doctrine que ce nouveau type existe.
Puis utilisons le type dans notre mapping ```config/entity/bookmark/Bookmark.orm.xml```
Pour aider Doctrine à s’y retrouver, il faut aussi ajouter un commentaire à la colonne dans la bdd.
On peut ajouter autant de types que l’on souhaite, ce qui nous permet de passer vraiment toutes les propriétés sous la forme de value-object. Et pour les value-object qui détiennent plusieurs données, comme une adresse postale, Doctrine propose un concept d’ Ouvre une nouvelle fenêtreembeddable qui permet de le répartir dans plusieurs champs de bdd.
Nous voilà avec une configuration doctrine complète. Commit : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/472a2ea7dcb8525c4ab946b19b54c8fc84d6b33c
On peut ajouter la commande suivante à notre série de commandes de validation de la qualité ```docker-compose exec web bin/console do:sc:va```
7.3. Because I’m API
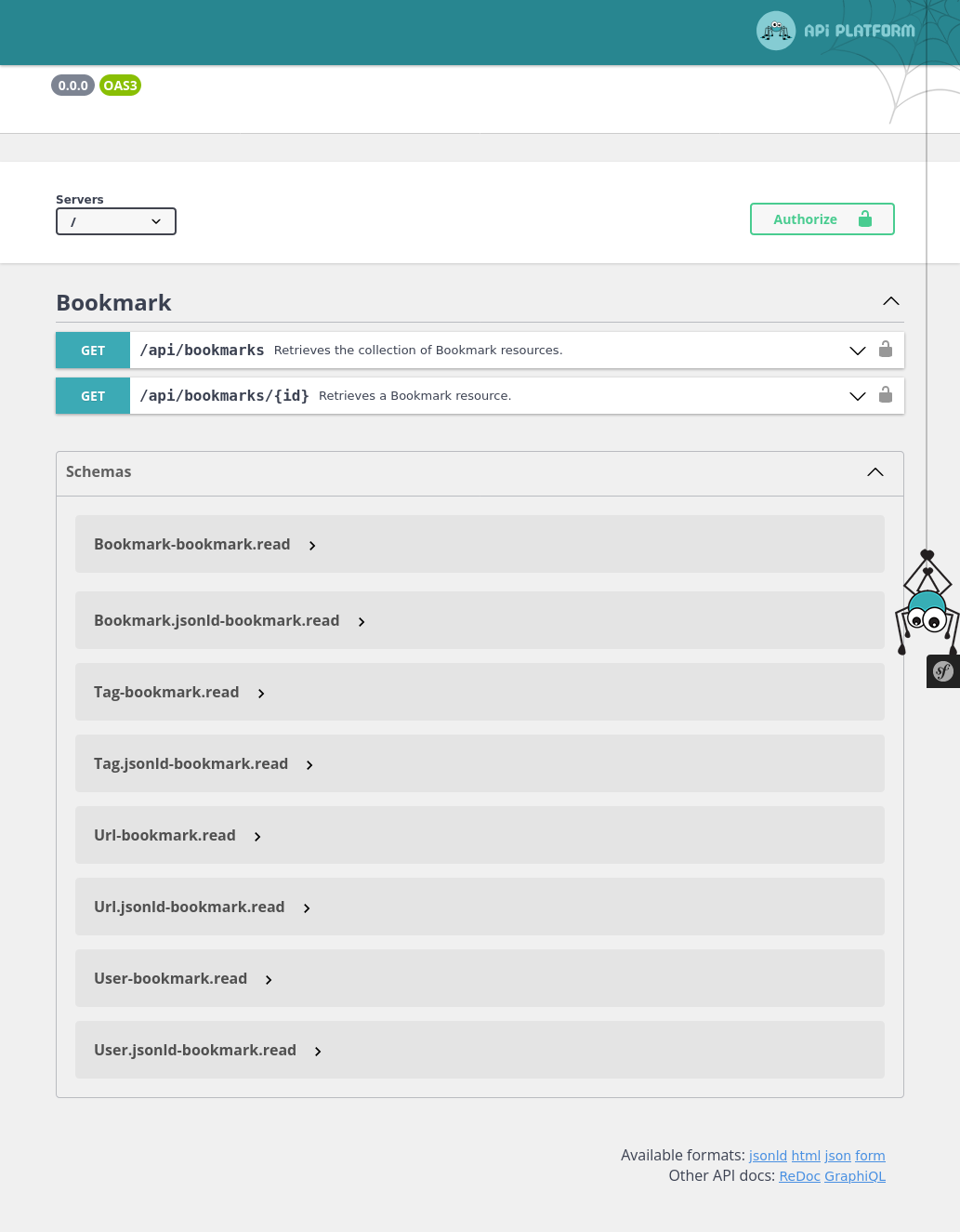
Il est maintenant possible d’exposer nos objets sur une Api contre un peu de configuration.
On reste là très proche de la configuration par défaut d’Api-Platform. Le point notable est uniquement le chemin pour trouver les différents mapping des objets exposés par l’Api. Voici. celui d’un bookmark.
On définit ici les deux opérations possibles : obtenir la liste des bookmarks, et obtenir un bookmark sur la base de son id.
On peut lancer la requête immédiatement, l’interface de swagger n’est peut-être pas la plus confortable mais elle est d’ores et déjà disponible sur Ouvre une nouvelle fenêtrehttp://0.0.0.0:9050/api/docs. On se heurte alors à une erreur :
. La raison en est simple, Doctrine ne travaille pas avec des tableaux, mais avec des objets qu’il nomme collections, pour les listes d’entités. C’est très pratique pour gérer les paginations. Imaginez que 100.000 tags soient associés à notre bookmark : la simple requête serait insupportable au serveur.Bref, il n’y a pas vraiment de solutions de contournement, et nous allons faire une entorse à notre DDD en définissant cette collection comme valide pour les propriétés des objets métier.
On fait de même avec les propriétés
puis . Puis on relance. Nouvelle erreur : . La raison en est tout simple : il recherche un bookmark, qui appartient à un utilisateur, qui a plusieurs bookmark, dont chacun appartient à un utilisateur, qui a plusieurs … etc. etc. Vous voyez la boucle. Pour y remédier, nous allons en même temps améliorer l’api. En fait on aurait envie de pouvoir lui dire que champ doit être affiché en fonction du contexte. On va va définir cela au niveau de la sérialisation dont le boulot est de transformer un objet métier dans sa représentation en une chaîne de caractères. Dans notre cas, il s’agit de JSON. Définissons les propriétés accessibles depuis un « groupe » de sérialisation.Puis on utilise ce groupe.
Nous voilà équipés d’un outillage pour personnaliser très finement ce que nous voudrons faire sortir via l’Api.
Voyons le résultat lorsque nous faisons la requête sur notre point d’Api : Ouvre une nouvelle fenêtrehttp://0.0.0.0:9050/api/bookmarks?page=1
Si vous regardez bien, il y a un problème ici : l’url est donnée sous la forme d’un tableau vide. C’est dû au serializer qui n’a pas su comment transformer la value-object Url en représentation valide pour la transmettre. Nous allons donc lui expliquer comment la sérialiser.
Puis il nous faut déclarer cette classe au composant de serialisation de Symfony. Nous allons le faire de manière générique en lui demandant d’enregistrer toute classe qui implémente
.Il faudra en faire de même pour tous les value-object, mais on pourra avantagement créer une interface pour les value object qui sont basée sur une seule valeur, et utiliser le même normaliseur.
D’un point de vue DDD, nous avons réalisé cette action sans jamais descendre explicitement dans la couche Domaine, nous n’avons pas utiliser le point d’entrée GetBookmark, mais nous allons laisser Doctrine faire ce travail pour nous. On peut tout à fait voir cette démarche comme contraire au DDD, mais c’est un compromis que nous assumons.
La couche domaine étant indépendante, nous sommes en mesure de la faire utiliser par plusieurs applications de nature très différentes comme cette API ou le fullstack de Cakephp.
Finalement, nous avons mis en place cette API sans grand effort ! Presque uniquement par de la configuration. Voilà un résultat tout à fait encourageant !
Le commit de ces changements : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/61d1063526dd389f2d9cb8c92780468dab1d821c
7.4. Un point d’API en écriture
Ajoutons mettons la possibilité de modifier un bookmark depuis l’API.
Nous lui disons ici que nous ajoutons une action de PATCH, c’est-à-dire de mettre à jour certaines données du bookmark. Pour cela nous lui donnons un input, qu’Api-Platform va tâcher de construire sur la base des paramètres passées par la requête HTTP. Puis nous lui précisons le processeur, la classe qui sera en mesure traiter la demande.
Nous faisons le choix de passer par le système de message de Symfony. Ce système permet d'émettre des messages, sous la forme d'une classe php (ce sera notre input), qui est ensuite intercepté par une autre classe capable de les traiter (notre handler).
Il nous faut maintenant définir que nos handler sont en mesures de traiter des messages envoyés via le messenger. Pour le faire de manière gloable, nous allons passer par une interface.
L’interface est vide, elle nous sert juste a bien identifier nos affaires.
Et maintenant, prévenons Symfony qu’il peut utiliser nos handler pour son messenger.
À présent, il nous faut implémenter côté infrastructure symfony l’outillage demandé par le domaine. Commençons par les repository.
Il va nous falloir implémenter l'interface pour retrouver l’utilisateur courant, mais puisque nous n’avons pas de système de sécurité côté symfony pour le moment, on va juste retourner null.
Pour faire fonctionner notre modification, il va falloir autoriser que la modification soit faite par un anonyme.
À présent, précisons à Doctrine qu’un tage peut être créé si un nouveau tag associé à un bookmark est identifié.
C’est parti pour faire une nouvelle requête.
Et voici le contenu de la réponse en 200.
Le patch fonctionne parfaitement :) Voici le commit : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/04dfcff3d279619c4cb216f59975b3cc826b0eb0
Renvoyer l’élément modifié ou juste une réponse 201 est un choix technique à faire. Les deux présentent leurs avantages et leurs inconvénients.
7.5. Donner de bons retours d’Api
Testons maintenant de transmettre cette même requête, mais avec une erreur.
Et voici le contenu de la réponse en 500.
Voilà une erreur qui n’est pas très explicite. L'exécution a été stoppée par la levée de l’exception. Pour pouvoir rendre de meilleures erreurs, nous allons nous interdire de lever des exceptions depuis les handler, mais renvoyer un objet qui a collecté ces erreurs à la place.
Avec un peu de recul, nous sommes en train de passer d’un tableau de string que nous nommons «erreur», à un objet collection qui va détenir une liste de violations, qui pourra détenir plus de valeur métier. Créons cette violation d’abord.
Puis le collecteur qui portera ces violations.
Nous pouvons maintenant modifier toutes nos création d’erreurs pour leur apporter bien plus de sens.
Puis on fait de même pour les autres validateurs. Toutes les violations se trouvent ainsi rassemblées en un seul endroit. On peut mettre à jour notre handler.
Quand tout est ok, on relance un test de modification en curl. Et on obtient un tableau vide ! Cela vient du fait que le serializer n’a pas su comment donner une version de sortie de la classe ViolationCollector. Nous allons donc lui expliquer.
Ici on utilise la capacité d’Api-Platform a récupérer les erreurs des contraintes de Symfony, pour en faire un affichage correct en sortie. Nous transformons donc nos violations en contraintes Symfony. Petit test.
Et voici le contenu de la réponse en 400.
Voilà une réponse tout à fait exploitable, même pour une application frontend ! Malgré sa cure de rafraîchissement, en regardant à nouveau le Handler, je dois avouer qu’il fait trop de tâches. Je ne peux résister de mettre en place une factory pour créer les value-object.
Et on modifie le handler pour y faire appel.
Notre value object implémente maintenant cette simple interface.
Il nous faut aussi mettre à jour le container de services côté Cakephp pour injecter ces nouvelles dépendances.
Au final, nous voici un handler beaucoup plus propre et compréhensible, avec une première partie sur la validation comprenant la création des value objects et une deuxième sur la mise à jour à proprement parler.
En voici le commit avec des modifications précises : Ouvre une nouvelle fenêtrehttps://github.com/vibby/cakephp-bookmarker-tutorial/commit/11ba291131b4dbc1c23c9e526ce5ed83011805bc
Je pourrais encore trouver de nombreux axes d’améliorations, mais je crois que nous allons nous arrêter ici :)
J’espère que vous avez apprécié le voyage !
Le mot de la fin
Que de chemin parcouru ! Notre application est maintenant opérationnelle et bien découpée en terme de responsabilités. Clairement, cette approche est un compromis entre le respect des principes du DDD et le pragmatisme d’un projet concret préexistant. Elle permet de limiter au maximum les dépendances entre les briqus logiciels, qui est un gage de meilleure tenue dans le temps par une maintenabilité grandement améliorée.
Cependant, un découpage plus important apporte également nécessairement plus de code et certains pourraient se sentir perdus dans cette organisation. Autre point négatif : la mise en place d’un tel paradigme nécessite l’implication de tous les acteurs du projet, y compris la partie « métier ». Mais le gain est énorme pour une application qui a pour objectif de vivre longtemps. D’ailleurs, depuis mon expérience, toute l’équipe a une meilleure confiance dans le projet dans ce type d’architecture.
Chez Troopers, nous avons travaillé sur 2 projets importants avec ce type de conversion. Si vous découvrez le DDD, je vous propose de commencer par le bouquin d’Eric Evans à l’origine de toute l’aventure : Domain-Driven Design: Tackling Complexity in the Heart of Software. Ouvre une nouvelle fenêtrehttps://www.chasse-aux-livres.fr/prix/0321125215/domain-driven-design-eric-evans
Pour aller plus loin sur le sujet, je vous conseille l’excellent article d’Alex So Yes : Ouvre une nouvelle fenêtrehttps://alexsoyes.com/ddd-domain-driven-design/#utiliser-ddd-dans-son-projet-tout-de-suite Vous avez un héritage logiciel ? Vous aimeriez en valoriser la partie métier, et moderniser son infrastructure ? Assurément cette méthode est faite pour vous, en séparant l’un de l’autre !


Vincent Beauvivre
Développeur back
Partager
